This writing system was created by Miguel Renart after an intense week of exams, when he finally returned his attention to developing something for a fictional setting he was working on with some friends. Although the setting is in Spanish, Daukin can be also used in English and German and probably also other European languages he's not fluent in.
Daukin is inspired on the genetic code and is intentionally degenerated in the same sense, meaning that the "code has redundancy but no ambiguity". The name "Daukin" is a homage to the great evolutionary biologist Richard Dawkins and it is the candid hope of the author that he would actually like this system.
(A perhaps better known degenerated code is the one used for phonewords as you can read an advertising asking to call 1-800-MYBANK and you will know to dial 1-800-692265. However, if given the numerical sequence you would not be able to univocally know the word which originated it.)
Daukin is based on eight symbols which are grouped into triplets to form a letter (DNA uses four symbols also in triplets). These eight symbols are already found on common fonts (Arial in this case) and are:
![]()
In this order they are capital Iota, capital Gamma, capital Tau, capital Pi, Cyrillic capital I, capital Delta, double dagger and capital Xi.
The coding of the triplets to form letters is as follows:
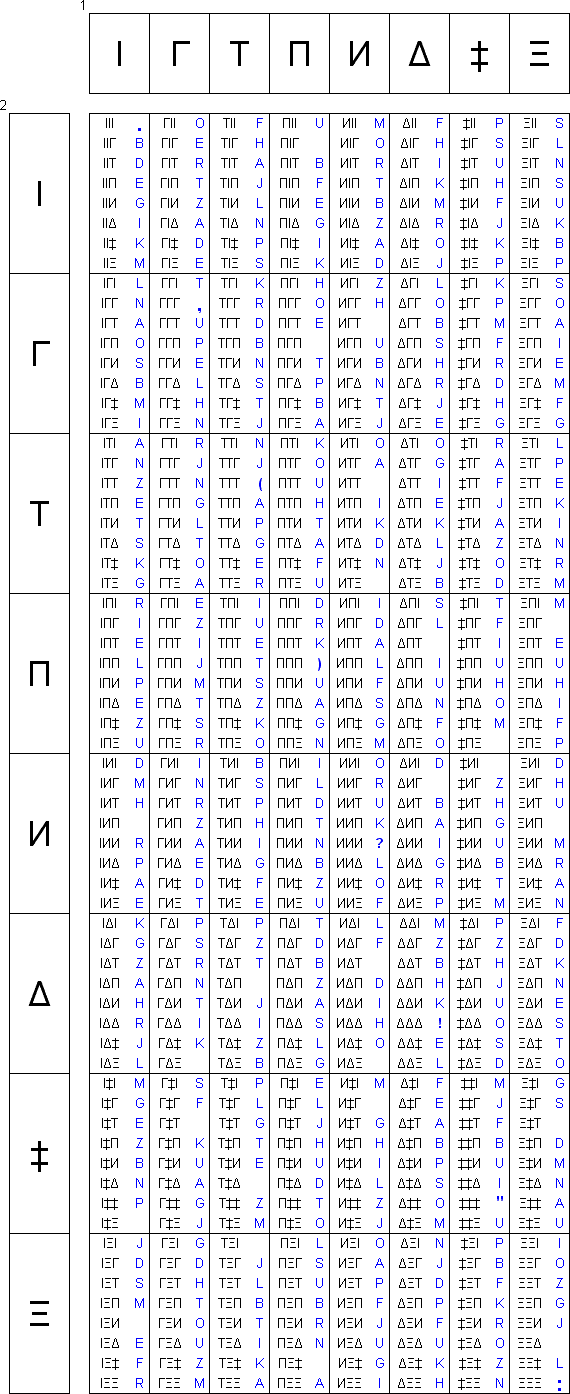
As seen, several consonants have been excluded since they have a pretty close phonetic equivalent in other letter.
Therefore "c" as in "ceiling" would use "zeiling" instead. "C" as in "car" would be "kar". "Q" would always be substituted for "k". "V" will tend to be used as "b", for example "behicle" or like an "f" in German: "Fier" instead of "Vier". "W" will be substituted by either "b" or "u" ("water" -> "uater"). "X" shall be replaced by "ks", "Y" mostly with "I" and the Spanish "ñ" by "ni".
Except those, all other letters and the "space" are represented at least 23 times each. This huge redundancy is necessary to the code as it enables to write any letter so that its reverse can be any of the other letters (or itself) which is the defining trait of this script and will be explained later on.
Common punctuation signs have also their code equivalent in the center diagonal of the code table, whenever there are three consecutive identical symbols. Daukin has no numerals and uses the common arabic ones (although there would be no problem from using roman numbering, which fits more to the "edgy" aspect of the Daukin symbols).
In this text "Symbol" refers to one of the eight characters that conform the code; "Triplet" refers to a specific arrangement of three such symbols in a given order; "Letter" refers to the letter from our usual alphabet obtained by decoding a given triplet in the table above.
The fictional setting is based on a confrontation between "light" and "darkness" so the usual "light" writing is explained first to be afterwards complemented with the ways of "darkness".
Daukin is commonly written from left to right and sometimes from top to bottom (similar to modern European languages). As each letter (+space and punctuation) is defined by three symbols, there is no need to space out symbols within a single word or sentence.
For example, OMNIGLOT can be written:
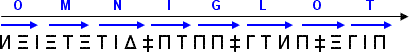
Each triplet (bold arrow) is read from left to right to yield a letter. The whole word is then read also from left to right (thin arrow).
Note that since there are 23 possibilities for each letter, this means that there are actually 78.310.985.281 (that is 238) different ways to write that word. So much for redundancy!
Since in this fictional setting agents of darkness are in risk of being exposed by servants of the light, they disguise their own messages within apparently normal texts using one or several of the following procedures. (Some of these have been inspired on what some real viruses do to "read" their genomes, others are simply logical possibilities but which have not been discovered yet in nature (to my knowledge)). Many are the paths of darkness.
A sequence of symbols in which each symbol is read from right to left. Thus the resulting reading direction is also from right to left.
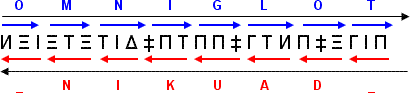
A sequence of symbols in which each triplet is read from right to left but words are read from left to right.
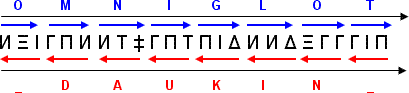
In theory both systems above can be combined so that we read each triplet from left to right but the whole text is read from right to left. That would be essentially the same as using our own alphabet to do this since by reading each triplet in the "right" direction we have taken out the redundancy which is the distinguishing feature of this code.
The two methods above share a limitation with punctuation signs. As all punctuation is done with triplets that are identical from both sides, any punctuation will stay identical when using either of the previous methods. Agents of darkness would have to construct their phrases to match the exact number of letters of the original or use an alternative. This is usually done by completely ignoring punctuation in the original text and then using a duplicated "_" to indicate a comma and three consecutive "_"for a fullstop.
Another alternative to avoid limitation with punctuation signs is a displacement of the reading frame. The first symbol is ignored and then each triplet is read from the last two symbols of the previous triplet with the first symbol of the next one.
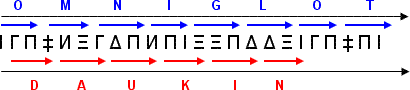
This procedure can thus bypass any triple symbol (that is, a punctuation mark) by placing two of them on one triplet and the other one on the next. However there is a catch on this. Although Daukin is designed to ensure that any given letter can yield any other one when read backwards, no such equivalence exists in this case. In the example above the word "daukin" should have been followed by an empty space, but there is no way to write the second "O" of "omniglot" so that while starting with an ?, the last two symbols would be coincident with the first ones of a "space".
The reason for this limitation is that any given symbol can have 64 possible combinations afterwards so in order to ensure full correspondence the code would have to be able to be 10 times larger (64 x 64 instead of 21 x 21).
Similar to the previous one, this procedure starts ignoring the first two symbols to alter the position of the reading frame. Although I was able in this occasion to find a "space" at the end, the same positive and negative aspects of the previous method apply to this one also.
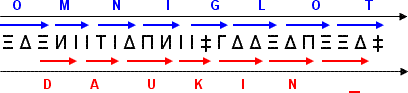
It is possible in theory to have at the same times three different messages at once using both of these methods: the original message, one at one step off and the last one at two steps off. However the practical difficulty renders this nearly impossible.
For those wondering, it is not possible to have more messages coded this way since a three step off reading frame yields exactly the same text as the original minus the first letter.
Instead of making a reading frame adjustment it is also possible to always ignore a certain symbol. This places a limitation on the "dark" message as none of its triplets may contain that specific symbol, but it adds flexibility when creating that message as it effectively adds the ignored symbol as a "wild card" on the original triplets.

It is usual that the first symbol in a string is the one to be omitted as it causes the first “dark” triplet to be already one step off. This is by no means necessary but if the symbol to be ignored is not represented in the first triplet, it would be read identically as “light” and “dark” … that is, unless an additional method is used, for exaple reading triplets from left to right.
This method has the highest theoretical information output, as we could have the original message and eight more, each of them with a different symbol ignored. Again, reality showes otherwise as it is already difficult enough to code a single message, never mind another seven simultaneously. Also, as there are only three possible reading frames, many letters will be repeated from one code to the other. Nevertheless, to show this possibility, here are the resulting “words” from the sequence above when ignoring different symbols:
Ι: OBUDGM Γ: DAUKIN Τ: OMNIGLS Π: OMNMDRM
И: GDSGLO Δ: OMZMPEE ‡: OMAMSEM Ξ: IZJMDRP
Another way to bypass the limitation of punctuation signs is to ignore always a symbol at specific position within each triplet, the first one in this example.
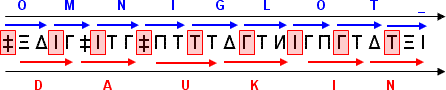
This way makes it much easier to find a matching letter since we have a "wild card" available for each triplet, but at the cost of text length. Since we are ignoring one third of our original text-string we can put less information in our "dark" message or we have to start from a longer original text. Note that I had to place a space at the end of "omniglot" in order to provide enough letters for "daukin".
Although this example ignores the first symbol, the method is exactly the same when ignoring the second or the third one. We could even ignore two symbols within a triplet, making it much easier to code but reducing our message to one third of the original.
As seen also with the off step procedures, we could have different messages from a single original string by ignoring the first, second and third symbol respectively. Perhaps more interesting, we can have a message both in the letters we are ignoring and those we intend to use, as an analogy to the introns in DNA. The symbols ignored in the example would be read as "PAA".
So far we have only seen encription methods which are derived from the fact that this code requires three independent symbols to form a letter; none of them would work with our normal alphabet. This last example however is perhaps the most simple way to code something: while meaning X instead write Y.
There are many arbitrary ways on how to make this correspondence: for example you could take our normal alphabet and code it backwards with itself. Therefore, if I would write an "A", I would be really meaning a "Z". A "B" would stand for an "Y" and so on.
Of the infinite ways to arrange it, I've chosen to make a correspondence based on geometry, similar to the way in which DNA fits one strang to the other.
![]()
Note that it is not necessary to have an even number of symbols, an earlier draft of Daukin used 5 symbols where one of them was complementary to itself.
I will not draw the example out since there are many letter equivalences that are not possible due to the limited number of combinations as explained, but just wanted to finish this code coming back on the DNA that inspired it.
Daukin is more a coding system than an alphabet, the 8 symbols were chosen to have a certain "dwarven" look in the sense of Tolkien scripts. Any alteration of these symbols to provide a different aesthetic is absolutely correct and legitimate. Writing Morse code with stars and slashes would not alter the code itself also.
(Symbols chosen so that reading inverted triplets with normal reading direction results in the same text)
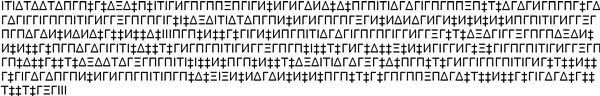
All human beings are born free and equal in dignity and rights. They
are endowed with reason and conscience and should act towards one another
in a spirit of brotherhood.
(Article 1 of the Universal Declaration of Human Rights)
If you have any questions about Daukin, you can contact Miguel at: miguelrenart[at]yahoo[dot]es
Information about Spanish | Useful Phrases | Silly Phrases | Numbers | Colours | Idioms | Family words | Time | Weather | Tongue twisters | Tower of Babel | Articles | Links | My Spanish learning adventures | My podcast about Spanish | Books about Spanish on: Amazon.com and Amazoncouk | Learn Spanish through stories
Constructed scripts for: Ainu | Arabic | Chinese languages | Dutch | English | Hawaiian | Hungarian | Japanese | Korean | Lingala | Malay & Indonesian | Persian | Tagalog / Filipino | Russian | Sanskrit | Spanish | Taino | Turkish | Vietnamese | Welsh | Other natural languages | Colour-based scripts | Tactile scripts | Phonetic/universal scripts | Constructed scripts for constructed languages | Adaptations of existing alphabets | Fictional alphabets | Magical alphabets | A-Z index | How to submit a constructed script
[top]

You can support this site by Buying Me A Coffee, and if you like what you see on this page, you can use the buttons below to share it with people you know.

If you like this site and find it useful, you can support it by making a donation via PayPal or Patreon, or by contributing in other ways. Omniglot is how I make my living.

Note: all links on this site to Amazon.com, Amazon.co.uk
and Amazon.fr
are affiliate links. This means I earn a commission if you click on any of them and buy something. So by clicking on these links you can help to support this site.
[top]









